天因你而笑
首页
分类与标签
动态
写文章
退出登录
✍️ 编辑文章
文章标题:
📁 分类:
🏷️ 标签 (用逗号分隔):
文章正文:
## AI的概念 只要一个计算机程序或系统展现出了某种类似于人类的“智能”(例如:解决复杂问题、理解自然语言、进行视觉识别等),无论其底层实现方式是什么,都可以被广义地称为人工智能。 在早期阶段,AI 主要通过显式编程和演绎法来构建。人类专家将知识转化为计算机可以执行的逻辑。 - **实现方式**:由无数个 `if-then-else` 语句堆叠而成的逻辑树或搜索算法。 - **经典案例**: - **游戏开发**:控制 NPC 行为的有限状态机 (FSM)。 - **路径规划**:用于地图导航的寻路算法。 - **医疗/工业**:将领域专家的经验硬编码进系统的“专家系统”。 - **智力竞技**:“深蓝”超级电脑(击败人类国际象棋冠军),其本质是依赖强大算力进行暴力搜索与规则评估,而非真正的“自我学习”。 但是这种AI存在极大的局限性: * **规则无法穷举**:现实世界充满了模糊性和边缘情况(Corner Cases),纯规则的 AI 无法将所有可能性一一写进代码里(例如:你无法用 `if-else` 写出识别不同品种、不同光线下一只猫的所有规则)。 * **缺乏成长性**:此类系统并不具备自我学习和进化的能力。环境一旦发生未被预设的改变,系统就会崩溃。 为了克服这些问题,计算机科学家改变了思路:不再尝试手写规则,而是让机器自己从海量的历史数据中“归纳”规则——机器学习。 ## 机器学习基本原理 机器学习:底层逻辑其实极度简单:**找一个合适的函数 $y = f(x)$** 这听起来似乎很反直觉。大模型能写代码、会作诗,但在数学本质上,它和初中数学题“已知几个点,求直线方程”没任何区别。唯一的不同在于规模:初中做的是二维直线的拟合,而 AI 是在一个上千亿维度的空间里,寻找一个极其扭曲、复杂的函数。 现实世界中的大量工作,本质上都可以看作是一个**函数映射 **。 - **翻译:** 输入中文 $x$ -> 映射函数 $f$ -> 输出英文 $y$。 - **图像识别:** 输入图片像素 $x$ -> 映射函数 $f$ -> 输出图像类别“猫” $y$。 - **对话:** 输入上文“你好” $x$ -> 映射函数 $f$ -> 输出下文“有什么能帮您的?” $y$。 机器学习的目标:找到一个准确的函数f能把输入$x$,映射到正确的输出 $y$。 - **早期AI:** 程序员使用编程语言表达这个函数。但是当问题复杂到一定维度时,人类不可能再手写出来这个规则。 - **机器学习:** 既然人写不出,那就设计一个自带几千亿个“旋钮(参数/权重)”的随机函数。然后用海量数据去“训练”它。通过“梯度下降”算法,机器一点点微调这几千亿个旋钮,直到这个高维函数能完美贴合真实数据。 * 初始时:这个函数所有旋钮是随机的(随机初始化)。 * 训练时:通过“梯度下降”,一点点微调这几千亿个旋钮。 * 最终目标:让函数输出尽量贴近真实数据。在高维空间中得到一个极度扭曲、但恰好“贴合数据”的函数 f > 也就是说AI 并没有“理解”猫是什么。它只是找到了一个极其扭曲的高维数学函数,当你输入“猫的像素”时,这个函数算出来的结果恰好落在“猫”的坐标区。 为什么“简单的拟合”能产生“智能”? 按照常理,“拟合”只是死记硬背。比如你把字典背下来,不代表你学会了写文章。但在 AI 领域,当参数量(旋钮)大到一定程度,且数据量大到一定程度时,发生了一个现象——能力涌现 (Emergence)。 在物理学中有一个概念叫相变 。水在 99°C 时,仅仅是热水。但是水在 100°C 时,突然变成了水蒸气,形态和性质完全变了。 在神经网络中,这种现象被称为“能力涌现”: 1. **碎片化阶段(小模型):** 模型记住了“苹果是红的”、“1+1=2”。这些知识是孤立的散点。 2. **回路连接阶段(中模型):** 模型开始把散点连成线。 3. **相变阶段(大模型):** 当参数密度达到临界点,无数个孤立的知识点突然连通成了一张巨大的网。 目前的研究人员的普遍看法是:涌现的真正原因在于压缩。 **压缩即智能:**模型为了用有限的参数(比如 70B)去拟合无限的互联网数据,模型被迫不能“死记硬背”,它被迫去寻找数据背后的规律。他会将数据抽象,归纳,压缩。 * 为了压缩所有关于“引力”的描述→ 它“发现”了公式形式的规律 * 为了压缩所有 Python 代码 → 它“学会”了编程结构和模式 > 目前大模型的最底层就是在做数据压缩。它把整个互联网的知识,压缩进了一个几 GB 的权重文件里。这种高效的压缩过程,倒逼出了我们眼中的“智能”。 既然底层是“拟合”,那么 AI 目前最大的弱点也就暴露了:**它很难处理“分布外 (Out-of-Distribution)”的数据。** - 人类的智能是基于**推理**的。你没见过粉色的狗,但如果你见到一只,你会推理出“这是一只被染色的狗”。 - AI 的智能是基于**统计**的。如果训练数据里从来没有“粉色狗”,它的那个高维函数在“粉色”和“狗”的交叉区域可能是一片未定义的混沌,它可能会自信地告诉你:“这是一只棉花糖”。 这就是为什么现在的大模型会产生“幻觉”——它走到了它那张地图(拟合函数)没有覆盖到的边缘地带,然后开始一本正经地胡说八道。 **反向诅咒:**并且这种知识压缩是有方向的。 如果你问 GPT-4:“Tom Cruise 的妈妈是谁?” 它可能立刻回答:“Mary Lee Pfeiffer”。(因为它压缩了 `Tom Cruise -> mother -> Mary` 这种模式)。 但如果你反过来问:“Mary Lee Pfeiffer 的儿子是谁?” 很多大模型会完全答不上来,或者开始胡编乱造。 这也揭示了目前“压缩路径”的局限性:**它建立的知识连接往往是单向的。** 这也是目前 AI 仅仅依靠“预测下一个 Token”这种训练方式的巨大隐患——它的“智能”在结构上与人类那种双向、多维的联想记忆还有本质区别。 ## 机器学习基本概念 机器学习是人工智能(AI)的一个重要分支,它赋予计算机无需被明确编程就能从数据中学习的能力。简单来说,机器学习的核心思想是:让计算机通过“经验”(数据)来提高在特定任务上的性能。 就像是教一个孩子学习:您不会告诉他“遇到这栋房子时必须这样做”,而是给他看成千上万的房子图片(数据),并告诉他哪些是房子(标签),然后他就能自己学会识别出一栋新出现的房子。 理解机器学习,需要抓住以下三个关键要素: 1. **任务(T, Task):** 机器想要完成的目标是什么?例如:识别图片中的物体、预测房价、翻译语言等。 2. **经验(E, Experience):** 机器用来学习和训练的数据集。数据量越大、质量越高,经验就越丰富。 3. **性能(P, Performance):** 如何衡量机器在完成任务时的表现?通常通过准确率(Accuracy)、误差率(Error Rate)等指标来量化。 这三个要素可以总结为:一个程序从经验中学习,以改进对任务的性能。 根据数据中是否包含“标签”以及学习方式的不同,机器学习通常可以分为以下几大类: 1. **监督学习:**数据集包含输入和对应的正确输出/标签。模型学习从输入到输出的映射关系。典型示例:分类(如:垃圾邮件识别、图像识别);回归(如:预测房价、股票价格)。 2. **无监督学习:**数据集没有标签。模型的目标是发现数据内在的结构、模式或关系。聚类(如:市场细分、客户分组);降维(如:数据可视化、特征提取)。 3. **强化学习:**模型(Agent)在一个环境中通过试错来学习。它根据行为获得的奖励或惩罚来调整自己的策略。自动驾驶、下棋(如AlphaGo)、机器人控制。 > 当我们在讨论机器学习的“学习”时,其本质是在寻找一个最优的数学函数 f(x),使得这个函数能够最好地拟合或描述我们所拥有的数据 D之间的关系。这个函数 f(x) 就是所谓的模型。当模型建立后,它对于未见过的新数据 x 就能给出准确的预测 y' = f(x')。这种从数据驱动到模型驱动的思维转变,是机器学习区别于传统编程(规则驱动)的核心所在。此外,一个经常被忽略的微小细节是:在实际应用中,特征工程——即如何把原始数据转化为模型更容易理解和学习的“特征”——其重要性往往高于选择复杂的模型本身。 ### 监督学习 监督学习算法通过带标签的训练数据进行学习。这里的“监督”意味着模型在训练时,就像在老师(标签)的指导下学习一样。 1. **训练数据的结构:**训练集中的每一个样本都包含一对数据: - **输入特征($X$):** 模型的输入,通常是向量或矩阵形式的数据(例如,房子的面积、卧室数量)。 - **正确输出/标签($Y$):** 与输入特征 $X$ 对应的期望结果或正确答案(例如,该房子的实际售价)。 2. **学习目标:**算法的目标是学习一个映射函数(或称模型)$f$:$$Y \approx f(X)$$ * 我们需要让这个函数能够将输入特征 $X$ 最好地映射到其对应的标签 $Y$。一旦模型学习完毕,它就可以用这个函数来预测新的、未见过的数据 $X'$ 的输出 $Y'$。 3. **学习过程(训练流程):** - **初始化模型:** 随机设定模型的参数。 - **前向传播:** 将训练数据 $X$ 输入到模型 $f$ 中,得到预测输出 $\hat{Y} = f(X)$。 - **计算损失:** 使用损失函数(Loss Function)计算预测输出 $\hat{Y}$ 与真实标签 $Y$ 之间的差异(即误差)。 - **反向传播与优化:** 利用优化算法(如梯度下降)沿着最小化损失函数的方向,调整模型的内部参数(权重和偏差)。 - **迭代:** 重复步骤,直到模型的误差收敛到可接受的水平。 4. **模型评估(测试与验证流程):**单靠“训练误差收敛”是不够的,模型必须具备“泛化能力”(在未知数据上表现良好)。 - **数据集划分:** 通常在训练前,会将整体数据按比例划分为训练集(Training Set)、验证集(Validation Set)和测试集(Test Set)。 - **验证调优:** 在训练的迭代过程中,定期使用验证集来测试模型,监控是否出现“过拟合”(Overfitting,死记硬背训练集导致泛化差)或“欠拟合”(Underfitting,没学到规律),并据此调整超参数。 - **最终测试:** 训练完全结束后,使用模型从未见过的测试集来评估其最终性能。 监督学习的目标是根据输入预测输出,而输出的“类型”不同,就形成了两种问题: 1. **分类**:预测离散标签。分类任务的目标是预测离散的类别标签,即让模型判断输入属于哪一类,例如判断邮件是否为垃圾邮件(二分类)、识别图片中的动物种类(多分类),或一部电影是否同时属于多个类别(多标签分类);常用算法包括逻辑回归、支持向量机、决策树、K近邻算法和神经网络等。 2. **回归**:预测连续数值。回归任务的目标是预测连续的数值输出,如根据历史数据预测股票价格、或依据房屋特征估算售价;常用算法有线性回归、岭回归、Lasso 回归、支持向量回归和深度学习模型。 ### 无监督学习 无监督学习算法通过无标签的训练数据进行学习。这里的“无监督”意味着模型在训练时,没有预设的正确答案或指导,必须自主地从数据中发现模式和结构。 1. 训练数据的结构:训练集中的样本只有输入特征($X$),而没有对应的标签($Y$)。 2. 学习目标:无监督学习算法的目标不是学习一个从 $X$ 到 $Y$ 的映射函数,而是学习数据的内在属性、分布规律、相似性或潜在维度。无监督学习旨在回答“数据是如何组织的?”和“数据中隐藏着哪些关系?” 3. 学习过程(与监督学习的对比): 无监督学习没有统一的训练流程(如监督学习中基于“误差”的反向传播),因为其目标不是最小化“预测误差”。它的学习机制是面向特定任务的,旨在优化其内部定义的目标函数。 > 由于缺乏标签来衡量误差,评估无监督学习模型的性能往往比监督学习更具挑战性,需要依赖内部评估指标(如聚类的紧密程度)或领域专家的评估。 无监督学习主要解决两类问题:**聚类问题**和**降维问题**。 1. **聚类:** 发现数据中的“群组”。聚类任务的目标是根据数据样本的相似性,将它们自动划分为若干个“簇”。它旨在实现“簇内相似度高,簇间相似度低”。例如,根据用户的购买行为进行市场细分、在社交网络中发现用户社区;常用算法包括 K-均值聚类 、DBSCAN 和层次聚类。 2. **降维:** 压缩数据,简化特征。降维任务的目标是将高维数据(具有大量特征)投影到低维空间,同时最大限度地保留数据中的重要信息。这有助于克服“维度灾难”、提高计算效率并实现数据可视化。例如,将高维的基因数据降至2维或3维以便可视化、在模型训练前进行特征提取以去除冗余;常用算法有主成分分析 (PCA)、t-SNE 和自编码器 。 ### 强化学习 强化学习算法通过智能体(Agent)与动态环境(Environment)的持续交互来进行学习。这里的“强化”意味着模型在训练时,就像一个在未知世界中摸索的婴儿,没有预设的标准答案,必须通过不断的“试错(Trial and Error)”,根据环境反馈的奖励或惩罚来调整自己的行为。 **训练数据的结构:** 训练数据不是预先收集好的静态数据集(如 X 和 Y 标签),而是模型在探索过程中动态生成的时间序列轨迹。它通常由不断循环的交互元组构成:当前状态(State)、采取的动作(Action)、环境反馈的即时奖励(Reward)以及进入的下一个状态(Next State)。 **学习目标:** 强化学习算法的目标是学习到一个最优的“策略(Policy)”。策略就是一个映射规则,告诉智能体在特定的状态下应该采取什么具体的动作。它的终极追求不是单次动作的成功,而是最大化长期的**累积奖励(Cumulative Reward)**。 **学习过程(与监督/无监督学习的对比):** 强化学习没有监督学习中清晰的“预测误差”反向传播,也没有无监督学习中静态的数据分布。它是一个闭环的动态博弈过程。由于缺乏即时的绝对正确答案,强化学习的学习机制面临两个独有的巨大挑战: 1. **延迟奖励(Delayed Reward):** 智能体的某个关键决策可能在很久之后才会产生明显的奖励或惩罚(例如下围棋,只有下完最后一步才知道输赢,但之前的每步落子都对结果有影响,算法必须学会如何将最终结果的“功劳”分配给之前的各个动作)。 2. **探索与利用的权衡(Exploration vs. Exploitation):** 智能体必须在“利用”已知能获得稳定小奖励的动作,和“探索”未知可能带来巨大收益的新动作之间找到平衡。评估强化学习模型的性能,通常通过观察其在环境中的累计得分趋势和收敛速度来判断。 强化学习主要解决复杂的**序列决策问题**,根据其优化核心的不同,主要分为两类核心方法(以及它们的结合): - **基于价值(Value-Based):** 学习评估“状态”或“动作”的潜在价值。其目标是构建一个价值函数,告诉智能体在某个状态下采取特定动作未来能拿到多少总分。智能体在决策时,总是贪婪地选择预期价值最高的动作。例如,通过评估迷宫中每个格子的得分来找到出口;常用算法包括 Q-Learning 和 DQN (Deep Q-Network)。 - **基于策略(Policy-Based):** 直接学习并优化智能体的行为策略本身。它不评估具体的得分,而是直接输出在特定状态下应该采取各个动作的概率分布。这种方法特别适合处理动作空间连续的任务(如控制机器人的关节转动角度或自动驾驶的方向盘);常用算法如 REINFORCE。 - *(注:如今最前沿的应用通常结合两者,称为 **Actor-Critic (演员-评论家)** 架构。“演员”负责根据策略做出动作,“评论家”负责评估动作的好坏并反馈指导。例如 ChatGPT 在对齐人类意图时使用的 PPO 算法。)* ## python常用库 ### numpy NumPy(Numerical Python)主要解决三件事: 1. 高效数组计算(比 Python 列表快很多) 2. 数学运算(线性代数、统计、傅里叶等) 3. 作为其他库的底层基础 NumPy提供了一个极其高效的 **N 维数组对象**。 虽然它看起来像 Python 的列表(List),但底层完全不同: - **同质性 (Homogeneous)**:List 里可以塞进字符串、整数、甚至另一个列表;但 NumPy 数组要求**所有元素类型必须一致**(通常是 `float64` 或 `int64`)。 - **连续内存**:Python List 在内存里是分散存储的“指针数组”;而 NumPy 在内存里申请的是一整块**连续的二进制数据**。这让 CPU 能够利用缓存预取(Cache Prefetching)和 SIMD 指令集瞬间处理一排数据。 1. 创建数组 ```python np.array([1, 2, 3]) np.array([[1, 2], [3, 4]]) np.zeros((3, 3)) # 全0 np.ones((2, 2)) # 全1 np.arange(0, 10, 2) # 类似 range np.linspace(0, 1, 5) # 等间距 np.eye(3) # 单位矩阵 ``` 2. 数组的属性 ```python a = np.array([1, 2, 3]) a.shape # 形状 a.ndim # 维度 a.dtype # 数据类型 a.size # 元素个数 ``` 3. 索引和切片 ```python a = np.array([10, 20, 30]) a[0] # 10 a[1:] # [20, 30] b = np.array([[1,2,3],[4,5,6]]) b[0,1] # 2 b[:,1] # 第二列 # 布尔索引 c = np.array([1, 2, 3, 4]) c[c > 2] # [3, 4] ``` 4. 广播机制:当你试图对两个形状(Shape)不一样的数组进行数学运算时,NumPy 不会立刻报错,而是会尝试把较小的数组“拉伸”(广播),使其形状与较大的数组兼容。 * **标量与数组**:`np.array([1, 2, 3]) + 10`。NumPy 会自动把 10 想象成 `[10, 10, 10]`,然后得出 `[11, 12, 13]`。 * **一维与二维**:一个 $3 \times 3$ 的矩阵减去一个包含 3 个元素的向量,NumPy 会自动把这个向量“复制”成三行,然后与矩阵逐行相减。这种机制让你在处理神经网络的偏置项(Bias)加法时,代码可以写得极其简洁。 ```python a = np.array([1, 2, 3]) b = 10 a + b # [11, 12, 13] a = np.array([[1],[2],[3]]) b = np.array([10,20,30]) a + b ``` 5. 常见运算 ```python # 彻底抛弃 for 循环,numpy中 加减乘除直接作用于整个数组 a = np.array([1, 2, 3]) b = np.array([4, 5, 6]) print(a * b) # 输出 [4, 10, 18] # 按轴计算 a = np.array([[1,2,3],[4,5,6]]) np.sum(a, axis=0) # 按列 np.sum(a, axis=1) # 按行 # 内置线性代数模块 np.dot(a, b) # 点积 a @ b # 推荐写法 np.linalg.inv(A) # 逆矩阵 np.linalg.det(A) # 行列式 np.linalg.eig(A) # 特征值 # 通用封装好的函数 np.sin(a) # 对所有元素求正弦 np.exp(a) # 对所有元素求 e 的指数 np.sqrt(a) # 对所有元素开根号 ``` ### Matplotlib ### Pandas Pandas 是 Python 数据分析领域最核心的库之一,可以理解为:**“带标签的超级表格工具(比 Excel 强很多)”** 它建立在 NumPy 之上,但更适合处理**结构化数据(表格数据)**。 Pandas 的一切操作,都围绕着这两个专门为“表格数据”设计的核心数据结构展开。 - **`Series` (一维列)**:你可以把它看作是一个 **“自带哈希键(Index)的 NumPy 一维数组”**。NumPy 数组只能靠隐式的数字下标(0, 1, 2)访问;而 Series 给每个元素贴上了显式的标签(比如 "A", "B", "C" 或时间戳)。 - **`DataFrame` (二维表)**:在底层,DataFrame 其实就是一个**字典 (Dictionary)**。它的 Key 是列名(比如“年 龄”、“收入”),它的 Value 是一个个长度相同的 `Series`。这意味着,DataFrame 的每一列可以是完全不同的数据类型(一列存字符串,一列存浮点数),这完美打破了 NumPy 的同构限制。 ## 人工智能数学基础 ### 微积分 #### 微分 极限是微积分的地基。它回答的问题是:当 $x$ 无限趋近于某个值时,$f(x) $ 趋向哪里?注意:这里不是"$x$ 等于 $a $ 时的值",而是"无限接近 $a $ 的过程中,函数值趋向的目标"。这个区别很重要——这表明了极限可以在函数在该点无定义时依然存在。 $$ \lim_{x \to a} f(x) = L $$ 导数:瞬间的变化率。几何上,$f'(x) $ 是函数曲线在 $x$ 处的切线斜率。物理上,位置的导数是速度,速度的导数是加速度。 $$ f'(x) = \lim_{h \to 0} \frac{f(x+h) - f(x)}{h} $$ **左导数 $f'_-(x)$:** 规定变量只能从比 $x$ 小的方向(左边)无限靠近 $x$。 * $$f'_-(x_0) = \lim_{h \to 0^-} \frac{f(x_0+h) - f(x_0)}{h}$$ **右导数 $f'_+(x)$:** 规定变量只能从比 $x$ 大的方向(右边)无限靠近 $x$。 * $$f'_+(x_0) = \lim_{h \to 0^+} \frac{f(x_0+h) - f(x_0)}{h}$$ 一个函数在某一点的导数存在的充分必要条件,该点的左导数必须等于右导数(且都存在)。即 $f'_-(x_0) = f'_+(x_0)$。 **常用求导规则:** | 规则 | 公式 | 例子 | | -------- | ------------------------------------------------------------ | ------------------------------ | | 常见函数 | $(e^x)' = e^x $,$(\ln x)' = \frac{1}{x} $,$(x^n)' = nx^{n-1} $ | — | | 链式法则 | $(f(g(x)))' = f'(g(x)) \cdot g'(x) $ | $(\sin x^2)' = 2x\cos x^2 $ | | 乘积法则 | $(fg)' = f'g + fg' $ | $(x \cdot e^x)' = e^x + xe^x $ | 导数的应用: 1. **找极值:** 极值点处切线水平,斜率为零,即 $f'(x) = 0 $。 2. **分析函数变化:** $f'(x) > 0 $ 说明函数在增,$f'(x) < 0 $ 说明在减,$f'(x) $ 从正变负说明过了一个峰顶。 3. **二阶导数:** $f''(x) $ 是导数的导数,描述变化率本身的变化——加速还是减速,曲线向上弯还是向下弯(凹凸性)。 #### 积分 积分回答:**变化加在一起是多少?**几何上,$\int_a^b f(x)\,dx $ 是函数曲线与 $x$ 轴之间围成的面积(带符号)。物理上,速度对时间积分得到位移。 $$ \int_a^b f(x)\,dx = \lim_{n\to\infty} \sum_{i=1}^n f(x_i)\Delta x $$ 把区间切成无数个极窄的矩形,每个矩形面积是 $f(x_i) \times \Delta x $,全部加起来的极限就是积分。 **常用积分规则:** | 规则 | 公式 | | -------- | ----------------------------------------- | | 幂函数 | $\int x^n\,dx = \frac{x^{n+1}}{n+1} + C $ | | 指数 | $\int e^x\,dx = e^x + C $ | | 换元法 | 令 $u = g(x) $,转化被积函数 | | 分部积分 | $\int u\,dv = uv - \int v\,du $ | #### 微积分 微积分基本定理:统一了积分和微分,揭示了“求切线(微分)”和“求面积(积分)”本质上互为逆运算。 $$ \frac{d}{dx}\int_a^x f(t)\,dt = f(x)\\ \int_a^b f(x)\,dx = F(b) - F(a) \quad \text{其中 } F' = f $$ > 要计算一段函数的面积,只需要找到原函数,代入端点相减。不用真的去累加无数个矩形。 #### 多元微分学 **偏导数**:固定其他变量,只对一个变量求导: $$ \frac{\partial f}{\partial x} \bigg|_{y \text{ 固定}} = \lim_{\Delta x \to 0} \frac{f(x+\Delta x, y) - f(x, y)}{\Delta x} $$ **高阶偏导数:**既然偏导数算出来的结果仍然是一个包含 $x, y$ 的函数,那么我们完全可以对这个新函数继续求偏导。有两种等价的常见写法: $$ \frac{\partial^2 f}{\partial y \partial x} \quad \text{或者简写为} \quad f_{xy} \\ (注意:\frac{\partial}{\partial y}(\frac{\partial f}{\partial x}) 意味着先对 x 导,再对 y 导) $$ **克莱罗定理:**只要函数是“足够平滑”的(二阶连续可导,现实世界的物理和工程函数 99.9% 都满足),那么混合偏导数与求导的先后顺序无关。 $$ \frac{\partial^2 f}{\partial x \partial y} = \frac{\partial^2 f}{\partial y \partial x} $$ ##### 方向导数和梯度 方向导数:偏导数只能看正东(x 轴)或正北(y 轴)。而方向导数用于计算沿着**任意给定方向**(由单位向量 $\vec{u}$ 决定)迈出一步时的瞬时变化率。只要曲面是平滑的,任意方向的斜率都可以用 $x$ 方向和 $y$ 方向的偏导数“按比例拼凑”出来。 $$ D_{\vec{u}}f = \frac{\partial f}{\partial x}u_1 + \frac{\partial f}{\partial y}u_2 $$ 既然你有无数个方向可以走,每个方向都有一个斜率(方向导数),那么自然会有一个问题:**哪个方向的向上的坡度最陡?** 这就是梯度的用武之地。梯度是一个向量,它永远指向当前位置上升最快(即方向导数最大)的方向。 并且,这个向量的长度(模长)正好等于那个最大的斜率值。 在数学上,函数 $f(x,y)$ 的梯度记作 $\nabla f$,它由函数对各个变量的偏导数组成: $$ \nabla f = \left\langle \frac{\partial f}{\partial x}, \frac{\partial f}{\partial y} \right\rangle $$ 方向导数和梯度之间有一个极其优美的数学关系式: $$ D_{\mathbf{u}}f = \nabla f \cdot \mathbf{u} = |\nabla f| |\mathbf{u}| \cos(\theta)\\ (其中\theta是梯度向量和你想走的方向向量之间的夹角,且 \mathbf{u} 是长度为 1 的单位向量,即 |\mathbf{u}|=1) $$ - **当 $\theta = 0^\circ$ 时**:$\cos(0)=1$,此时方向导数达到**最大值**,等于梯度的长度。这意味着**顺着梯度的方向走,上升最快**。 - **当 $\theta = 180^\circ$ 时**:$\cos(180^\circ)=-1$,此时方向导数达到**最小值**。这意味着**逆着梯度的方向走,下降最快**。 - **当 $\theta = 90^\circ$ 时**:$\cos(90^\circ)=0$,此时方向导数为 0。这意味着如果你垂直于梯度方向走,你的高度不会发生变化(你正在沿着**等高线**行走)。 机器学习中的**梯度下降法(Gradient Descent):**就是让模型计算出 $\nabla f$,然后加上负号($-\nabla f$),顺着这个“最陡的下坡方向”更新权重矩阵,直奔误差最小的谷底。 #### 泰勒展开 在数学和工程中,我们经常遇到一些非常难缠的“超越函数”,比如 $\sin(x)$、$e^x$、$\ln(x)$。计算机的底层逻辑只有加法和乘法,它根本不知道怎么直接计算 $\sin(1.2)$ 的精确值。 **泰勒展开的核心思想就是:模仿。**它提出了一种绝妙的策略:既然复杂的曲线很难处理,我们能不能用最简单的**多项式**(只有加减乘除和整数次幂,如 $a + bx + cx^2$)来“伪装”成这个复杂的曲线? 试想你要在一个特定的点(比如 $x=0$)附近模仿一条曲线: - **0阶模仿(常数):** 只要在这个点的值一样就行。这相当于用一条水平直线穿过该点。(非常粗糙) - **1阶模仿(线性):** 不仅值一样,这个点的**斜率(一阶导数)**也要一样。这就是该点的切线。(在点附近比较像了) - **2阶模仿(二次型):** 值一样、斜率一样,**弯曲程度(二阶导数)**也要一样。这就用到了一条抛物线。 - **高阶模仿:** 不断让更高阶的导数(变化率的变化率...)相等。 泰勒展开的结论是:**只要我们让多项式在某一点的所有阶导数,都和原函数一模一样,这个多项式就会完美地贴合原函数。** 把上述的“模仿”过程翻译成严格的数学公式,假设我们要在一个已知点 $x=a$ 附近展开一个平滑函数 $f(x) $,公式如下: $$f(x) = f(a) + f'(a)(x-a) + \frac{f''(a)}{2!}(x-a)^2 + \dots + \frac{f^{(n)}(a)}{n!}(x-a)^n + \dots$$ - $f'(a)$ 是第一阶导数,控制斜率。 - $f''(a)$ 是第二阶导数,控制曲率。除以 $2!$ 是为了求导后能刚好与系数抵消。 - 每增加一项,我们对原曲线的“刻画”就深入一个层次。当项数 $n $ 趋近于无穷大时,多项式就**等于**原函数。 **特例(麦克劳林展开):** 当我们在原点 $x=0$ 处进行展开时,公式变得极其简洁,这被称为麦克劳林级数。比如 $e^x$ 的展开式非常漂亮: $$e^x = 1 + x + \frac{x^2}{2!} + \frac{x^3}{3!} + \dots$$ #### 多元函数的泰勒展开 泰勒展开的核心在于:**用多项式在某一点附近逼近一个复杂的函数**。 对于多元函数 $f(\mathbf{x})$,如果它在点 $\mathbf{a}$ 附近具有连续的直到 $n+1$ 阶的偏导数,我们就可以将其展开为以 $(\mathbf{x}-\mathbf{a})$ 为变量的幂级数。 设 $z = f(x, y)$ 在点 $(x_0, y_0)$ 附近展开,增量为 $h = x - x_0, k = y - y_0$。其二阶展开式如下: $$f(x_0+h, y_0+k) \approx f(x_0, y_0) + \left( h\frac{\partial f}{\partial x} + k\frac{\partial f}{\partial y} \right) + \frac{1}{2!} \left( h^2\frac{\partial^2 f}{\partial x^2} + 2hk\frac{\partial^2 f}{\partial x \partial y} + k^2\frac{\partial^2 f}{\partial y^2} \right)$$ - **零阶项**:函数在该点的值。 - **一阶项**:切平面,代表函数的线性变化(偏导数)。 - **二阶项**:描述曲面的弯曲程度(曲率)。 为了简洁并推广到 $n $ 元函数,我们通常使用向量表示。设 $\mathbf{x} = [x_1, x_2, \dots, x_n]^T$,在 $\mathbf{a}$ 点展开: $$f(\mathbf{x}) \approx f(\mathbf{a}) + \nabla f(\mathbf{a})^T (\mathbf{x} - \mathbf{a}) + \frac{1}{2!} (\mathbf{x} - \mathbf{a})^T \mathbf{H}(\mathbf{a}) (\mathbf{x} - \mathbf{a})$$ 其中: - $\nabla f(\mathbf{a})$ 是 **梯度向量 (Gradient)**,包含所有一阶偏导数。 - $\mathbf{H}(\mathbf{a})$ 是 **海森矩阵 (Hessian Matrix)**,其元素为二阶混合偏导数 $H_{ij} = \frac{\partial^2 f}{\partial x_i \partial x_j}$。 > **一阶展开**:相当于在曲面上找一个**切平面**。如果你只看一阶项,函数在该点附近看起来是“平”的。 > > **二阶展开**:相当于用一个**二次曲面(抛物面)**去贴合原曲面。通过海森矩阵的特征值,我们可以判断该点是极小值点(凹)、极大值点(凸)还是鞍点。 ### 线性代数 #### 向量 **标量(Scalar)**:只有大小,没有方向 例如:温度 25°C、质量 10kg **向量(Vector)**:既有大小,又有方向 例如:速度(向东 10 m/s)、力(向下 5 N) 物理视角:带方向箭头的量,既有大小又有方向。 几何视角:空间中的坐标 n维向量的坐标表示: $$ \vec{v} = (x_1, x_2, \dots, x_n) $$ 线性代数视角:向量是一个可以进行线性运算的对象 列向量(线性代数标准写法) $$ \vec{v} = \begin{pmatrix} x_1 \\ x_2 \\ \vdots \\ x_n \end{pmatrix} $$ **行向量**为列向量的转置:$\vec{v}^T = (x_1, x_2, \dots, x_n) $ > 线性代数中,默认向量均为**列向量**。 **向量的基本运算** **向量加法**:对应分量相加 $$ \vec{u} + \vec{v} = \begin{pmatrix} u_1 + v_1 \\ u_2 + v_2 \\ \vdots \end{pmatrix} $$ **数乘(标量乘法)**:每个分量乘以标量 $k $ $$ k\vec{v} = \begin{pmatrix} kx_1 \\ kx_2 \\ \vdots \end{pmatrix} $$ **线性组合**:加法与数乘的组合 $$ a\vec{u} + b\vec{v} $$ 这两种运算是线性代数中最核心的操作,向量空间的一切结构都建立在此之上。 **向量的模(长度)** $$ |\vec{v}| = \sqrt{x_1^2 + x_2^2 + \dots + x_n^2} $$ **单位向量**:模为 1 的向量,$\hat{v} = \dfrac{\vec{v}}{|\vec{v}|} $ **向量的内积:**列向量 $\vec{v}*\vec{v}^T $,变成了一个标量,等于对应位置相乘再相加。 向量的范数:"向量的长度"的推广。给定向量 $\vec{v} = (v_1, v_2, \dots, v_n) $: * **L2 范数**(欧式距离,最常用)就是直线距离,勾股定理的推广。 $$ \|\vec{v}\|_2 = \sqrt{v_1^2 + v_2^2 + \dots + v_n^2} $$ * **L1 范数**(曼哈顿距离)想象在棋盘格城市里走路,只能横走竖走,不能斜穿。 $$ \|\vec{v}\|_1 = |v_1| + |v_2| + \dots + |v_n| $$ * **L∞ 范数**(切比雪夫距离)只取最大的那个分量。 $$ \|\vec{v}\|_\infty = \max(|v_1|, |v_2|, \dots, |v_n|) $$ > L2 范数用于正则化时(Ridge),会让所有权重都变小但不为零,适合特征之间都有贡献的情况。 > > L1 范数用于正则化时(Lasso),会让很多权重直接变成零,自动做特征选择——这是因为菱形的"角"正好落在坐标轴上。这个几何直觉很重要:损失函数的等高线碰到 L1 的菱形,最容易在角上相切,而角恰好是某个维度为零的地方。 > > L2 范数还用来计算向量的"单位化":$\hat{v} = \vec{v}/\|\vec{v}\|_2 $,让向量长度变为 1,只保留方向——神经网络里归一化操作的基础。 > > 简单说:L2 是"自然的距离",L1 是"产生稀疏性的工具",两者在机器学习里都是高频工具。 **理解向量:** 第一步,把向量理解成"箭头"。它有方向和长度,(2, 1) 就是"向右走2步,再向上走1步"。这是几何视角,非常直观。 第二步,意识到向量是一种"操作"。数乘($k\vec{v} $)让它变长变短,加法($\vec{u}+\vec{v} $)让两个操作叠加。这两件事合起来叫线性运算,是线性代数唯一关心的事。 第三步,问一个大问题:这些向量的所有线性组合能"够到"哪些地方?这个集合叫做**张成空间(span)**。如果两个向量线性无关,它们张成整个平面;如果线性相关(一个是另一个的倍数),张成空间就只是一条线——维度"塌陷"了。 > "张成整个平面"的意思是:平面上随便给你一个点,我都能靠这两个向量的线性组合走到那里。线性无关保证的,就是这件事一定能做到——两个方向不重叠,各自提供一个独立的"移动维度",合起来就能覆盖二维平面的每一个角落。 #### AI中的向量 AI无法直接处理文字、图片、声音。它能处理的只有数字。所以第一步,永远是把世界上的一切**变成向量**。 一张图片 → 每个像素的RGB值 → 一个几十万维的向量 一段文字 → 每个词的语义坐标 → 一个几百维的向量 一首歌 → 频谱特征 → 一个向量 这个过程叫**嵌入**,这是目前AI理解世界的入口。 向量空间:当你把大量文字喂给AI训练,它会自动学到一种排列方式,使得语义相近的词,在向量空间里距离也相近。 **向量运算 = 语义运算**:这是让所有人震惊的发现。Word2Vec 模型里有一个著名的例子: $$ \vec{\text{国王}} - \vec{\text{男人}} + \vec{\text{女人}} \approx \vec{\text{女王}} $$ 减法在向量空间里对应的是"去掉某个属性",加法是"叠加某个属性"。向量的线性运算,直接变成了对概念的操作。 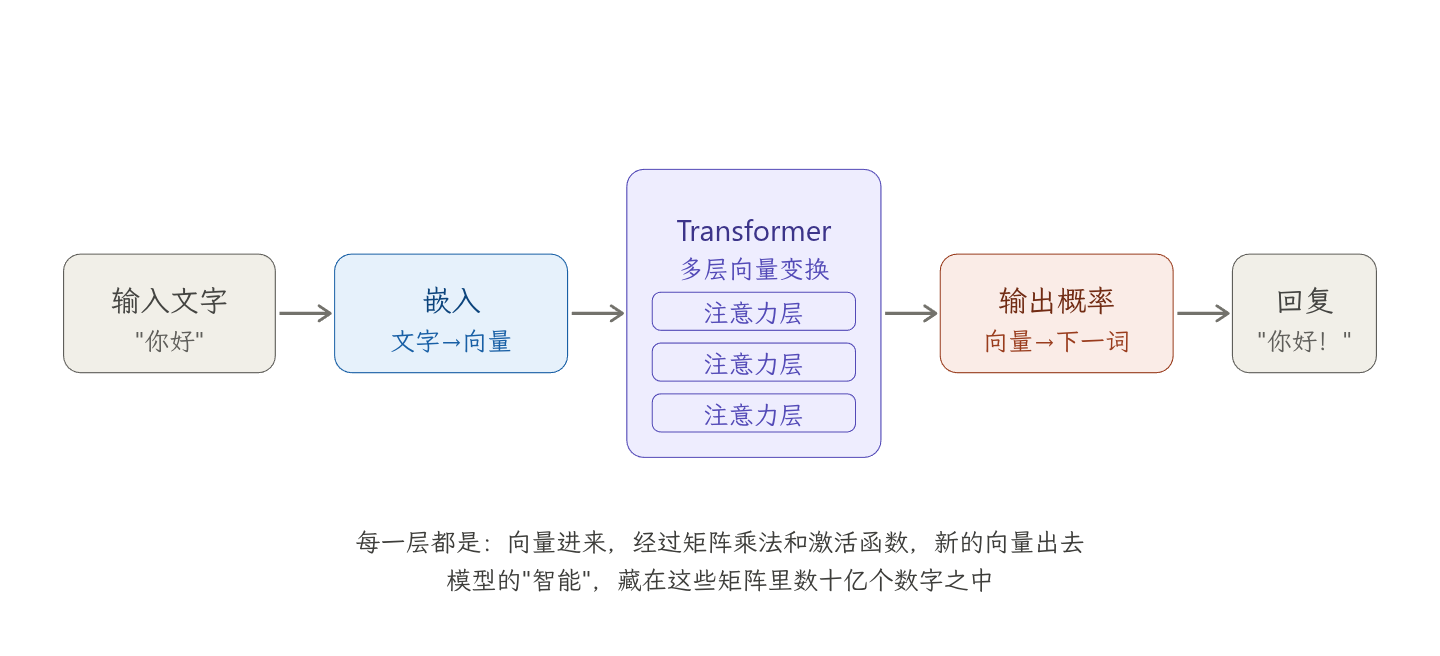 每一层 Transformer 做的事,本质上就是你在线性代数里学的:把一个向量乘以一个矩阵,得到一个新的向量。乘了几百层之后,输入的语义被提炼、变换、重新编码,最终模型能预测出"下一个词最可能是什么"。 #### 矩阵 一个 $m \times n $ 的矩阵有 $m $ 行、$n $ 列: $A = \begin{pmatrix} a_{11} & a_{12} & a_{13} \\ a_{21} & a_{22} & a_{23} \end{pmatrix}$ 矩阵乘向量 $A\vec{x} $,就是把向量 $\vec{x} $($n $ 维)变换成新向量($m $ 维)。 1. **转置 $A^T $**:把行列互换。$(A^T)_{ij} = A_{ji} $。在 AI 里极其常见,注意力机制里的 $QK^T $ 就是这个。 2. **逆矩阵 $A^{-1} $**:满足 $AA^{-1} = I $(单位矩阵)的矩阵,相当于"撤销这次变换"。只有方阵且行列式不为零时才存在。 3. **行列式 $\det(A) $**:一个数,描述矩阵变换后**面积/体积的缩放比例**。行列式为 0 意味着空间被压扁,变换不可逆。 4. **秩 $\text{rank}(A) $**:矩阵变换后,输出空间的维数。一个 $3\times3 $ 矩阵,秩为 2 意味着它把三维空间压成了一个平面。 #### 特征值 矩阵不仅仅是数字的表格,它本质上是对空间的一种“变换(Transformation)”。想象一个画满网格线的弹性橡胶平面(二维坐标系)。当你用一个 $2 \times 2$ 的矩阵去乘以这个平面上的所有向量时,这个橡胶平面会被拉伸、挤压、翻转或者旋转。在这个剧烈的“空间形变”中,绝大多数的向量(带有方向的箭头)不仅长度改变了,**方向也跟着偏转了**。但是,总有那么几个极其“固执”的特殊向量。在这个矩阵的拉扯下,它们**只改变了长度,却死死保持着原来的方向(或者变成了完全相反的反方向)**。 - 这些“宁死不屈,绝不偏航”的特殊向量,就是**特征向量**。 - 特征向量被拉伸或压缩的“倍数”,就是对应的**特征值**。 把上述的几何直觉翻译成数学语言,极其简洁: $$ A\mathbf{v} = \lambda\mathbf{v} $$ - $A$ 是一个方阵(代表空间的变换规则)。 - $\mathbf{v}$ 是一个非零向量(也就是**特征向量**)。 - $\lambda$ 是一个常数(也就是**特征值**)。 这个等式的左边是“矩阵乘法(复杂的变换)”,右边是“标量乘法(简单的拉伸)”。**特征值的特别之处在于,它把极其复杂的矩阵运算,在特定的方向(特征向量)上,降维成了最简单的小学乘法。** - 如果 $\lambda = 2$,说明特征向量被拉长了 2 倍。 - 如果 $\lambda = \frac{1}{2}$,说明被压缩了一半。 - 如果 $\lambda = -1$,说明方向发生了 180 度的翻转,但长度不变。 ##### 特征向量的求解 $$ A\mathbf{v} - \lambda\mathbf{v} = \mathbf{0}\\ 提取公因式 \mathbf{v}(注意,\lambda 是一个数字,不能直接和矩阵相减,所以我们要借用单位矩阵 I)\\ (A - \lambda I)\mathbf{v} = \mathbf{0} $$ 因为规定特征向量 $\mathbf{v}$ 不能是零向量($\mathbf{v} \neq \mathbf{0}$),那么上面这个方程要有非零解,根据线性代数法则,括号里的这个新矩阵 $(A - \lambda I)$ 必须是一个“奇异矩阵”(即它把空间压扁了,体积变成了 0)。这就引出了计算特征值的核心公式——**特征方程(Characteristic Equation)**: $$ \det(A - \lambda I) = 0 $$ 只要解出这个多项式方程的根,你就能得到矩阵 $A $ 的所有特征值 $\lambda$。 #### 二次型 简单来说,二次型就是一个“每一项的次数都恰好为 2”的多项式。包含 $n $ 个变量 $x_1, x_2, \dots, x_n$ 的二次型可以写成: $$ f(x_1, x_2, \dots, x_n) = \sum_{i=1}^{n}\sum_{j=1}^{n} a_{ij}x_i x_j $$ **单变量:** $f(x) = 3x^2$ (这是最简单的二次型) **双变量:** $f(x, y) = 2x^2 + 5xy - 3y^2$ (每一项的次数都是 2:$x^2$ 是 2 次,$xy$ 是 $1+1=2$ 次,$y^2$ 是 2 次) **三变量:** $f(x, y, z) = x^2 + 2y^2 + 3z^2 + 4xy + 5xz + 6yz$ **反例**(以下**不是**二次型): - $f(x, y) = x^2 + y$ (包含 1 次项 $y$) - $f(x, y) = x^2 + xy + 3$ (包含常数项 3,即 0 次项) 二次型可以完美地转化为矩阵乘法。这使得我们可以利用线性代数工具来分析它。任何一个二次型都可以写成如下形式: $$ f(\mathbf{x}) = \mathbf{x}^T A \mathbf{x}\\ (其中,\mathbf{x}是变量构成的列向量,A是一个实对称矩阵) $$ 矩阵A的构造规则非常简单: 1. 平方项 $x_i^2$ 的系数,放在矩阵主对角线上的 $(i, i)$ 位置。 2. 交叉项 $x_i x_j$ 的系数,**平分一半**,分别放在矩阵的 $(i, j)$ 和 $(j, i)$ 位置。 ##### 标准化 含有交叉项(如 $xy$, $yz$)的二次型很难直观看出它的性质。因此,我们需要对其进行“坐标变换”,把交叉项消去,使其变成只含有平方项的形式,这被称为**标准型**: $$f = d_1 y_1^2 + d_2 y_2^2 + \dots + d_n y_n^2$$ 在几何上,消除交叉项的本质是**旋转坐标系**,让新的坐标轴与二次型(代表的几何图形)的主轴对齐。 常用的方法有两种: 1. **配方法(拉格朗日法):** 也就是我们在初高中学的完全平方式凑法,通过代数变换消去交叉项。 2. **正交变换法(特征值法):** 这是最重要的方法。由于矩阵 $A $ 是实对称矩阵,它一定可以对角化。我们求解 $A $ 的**特征值** $\lambda_1, \lambda_2, \dots, \lambda_n$,这些特征值就是标准型中的系数 $d_i$。对应的特征向量决定了坐标轴旋转的方向。 ##### 正定 在很多应用中,我们最关心的是:**对于任何非零输入,这个二次型的值是正还是负?** 这引出了二次型的“定性”分类(以标准型 $f = \lambda_1 y_1^2 + \dots + \lambda_n y_n^2$ 为例): - **正定 (Positive Definite):** 对于任何非零向量 $\mathbf{x}$,都有 $f(\mathbf{x}) > 0$。 - *条件:* 所有特征值 $\lambda_i > 0$(或者所有顺序主子式 $> 0$)。 - *几何直觉:* 像一个开口向上的完美“碗”形(抛物面),最低点是原点。 - **负定 (Negative Definite):** 对于任何非零向量 $\mathbf{x}$,都有 $f(\mathbf{x}) < 0$。 - *条件:* 所有特征值 $\lambda_i < 0$。 - *几何直觉:* 开口向下的“碗”。 - **不定 (Indefinite):** 函数值有正有负。 - *条件:* 特征值有正有负。 - *几何直觉:* 像一个“马鞍面”(在某个方向看向上弯,另一个方向向下弯)。 #### 矩阵和向量求导 矩阵和向量的求导,本质上只是把标量微积分的结果,按照特定的规则整齐地排列在向量或矩阵中。 它是一种“记账方式”,帮我们批量处理大量变量的偏导数。 - **分子布局**:求导结果的维度与分子保持一致。这种布局在纯数学中更常见,它生成的雅可比矩阵(Jacobian)符合传统的数学定义。 - **分母布局**:求导结果的维度与分母保持一致。**这是机器学习(如深度学习、优化算法)中最常用的布局**。因为在梯度下降中,我们需要用导数去更新参数 $\mathbf{x}$,即 $\mathbf{x} \leftarrow \mathbf{x} - \alpha \nabla_{\mathbf{x}} f$,导数的维度如果和参数 $\mathbf{x}$(分母)一样,就可以直接相减。 ##### 标量对向量求导 这是深度学习中最常见的情况,比如我们计算损失函数(标量 $L$)对权重(向量 $\mathbf{w}$)的梯度。 假设有一个标量函数 $f(\mathbf{x})$,其中自变量 $\mathbf{x}$ 是一个包含 $n $ 个元素的列向量 $\mathbf{x} = [x_1, x_2, \dots, x_n]^T$。 标量 $f$ 对向量 $\mathbf{x}$ 的导数(即**梯度**),就是 $f$ 对 $\mathbf{x}$ 中每一个元素分别求偏导,然后按照 $\mathbf{x}$ 原本的形状排成一个列向量: $$\frac{\partial f}{\partial \mathbf{x}} = \begin{bmatrix} \frac{\partial f}{\partial x_1} \\ \frac{\partial f}{\partial x_2} \\ \vdots \\ \frac{\partial f}{\partial x_n} \end{bmatrix}$$ **常用法则:** - 线性关系:$f(\mathbf{x}) = \mathbf{w}^T\mathbf{x}$ 或 $f(\mathbf{x}) = \mathbf{x}^T\mathbf{w}$,则 $\frac{\partial f}{\partial \mathbf{x}} = \mathbf{w}$ - 二次型:$f(\mathbf{x}) = \mathbf{x}^T A \mathbf{x}$,则 $\frac{\partial f}{\partial \mathbf{x}} = (A + A^T)\mathbf{x}$。(如果 $A$ 是对称矩阵,则结果为 $2A\mathbf{x}$) ##### 向量对向量求导 假设函数的输出不再是一个数,而是一个包含 $m $ 个元素的列向量 $\mathbf{y} = [y_1, \dots, y_m]^T$,自变量依然是 $n $ 维列向量 $\mathbf{x}$。此时,$\mathbf{y}$ 中的每一个元素 $y_i$ 都要对 $\mathbf{x}$ 中的每一个元素 $x_j$ 求导。结果会形成一个 $m \times n $ 的矩阵,这就是著名的 **雅可比矩阵(Jacobian Matrix)**。 在分母布局下,为了保持与链式法则的兼容,雅可比矩阵通常定义为(也有文献定义为其转置,需注意上下文): $$\frac{\partial \mathbf{y}}{\partial \mathbf{x}} = \begin{bmatrix} \frac{\partial y_1}{\partial x_1} & \frac{\partial y_2}{\partial x_1} & \dots & \frac{\partial y_m}{\partial x_1} \\ \frac{\partial y_1}{\partial x_2} & \frac{\partial y_2}{\partial x_2} & \dots & \frac{\partial y_m}{\partial x_2} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{\partial y_1}{\partial x_n} & \frac{\partial y_2}{\partial x_n} & \dots & \frac{\partial y_m}{\partial x_n} \end{bmatrix}$$ **常用法则:** - 线性变换:$\mathbf{y} = A\mathbf{x}$,则 $\frac{\partial \mathbf{y}}{\partial \mathbf{x}} = A^T$ (注意这里的转置是因为我们使用了分母布局) ##### 标量对矩阵求导 假设损失函数是一个标量 $L$,而网络层中的权重是一个矩阵 $W$(尺寸为 $m \times n $)。 标量对矩阵的求导,结果依然是一个 $m \times n $ 的矩阵,其中每个位置的元素就是标量对该位置参数的偏导数: $$\frac{\partial L}{\partial W} = \begin{bmatrix} \frac{\partial L}{\partial W_{11}} & \dots & \frac{\partial L}{\partial W_{1n}} \\ \vdots & \ddots & \vdots \\ \frac{\partial L}{\partial W_{m1}} & \dots & \frac{\partial L}{\partial W_{mn}} \end{bmatrix}$$ **常用法则(迹技巧 Trace Trick):** 在推导标量对矩阵的导数时,经常引入矩阵的迹(Trace,对角线元素之和)。例如: $\frac{\partial \text{tr}(AW)}{\partial W} = A^T$ #### 奇异值分解 奇异值分解(Singular Value Decomposition,简称 SVD) SVD 的核心思想是:任意一个大小为 $m \times n $ 的实数矩阵 $A$(无论它是方阵还是长方形矩阵),都可以被分解为三个特殊矩阵的乘积: $$ A = U \Sigma V^T $$ - **$V^T$ (右奇异矩阵的转置):** 这是一个 $n \times n$ 的正交矩阵。 - 它的行向量(即 $V$ 的列向量)被称为右奇异向量。 - 正交矩阵的特性是 $V^T V = I$。在几何上,乘以一个正交矩阵相当于对空间进行旋转或镜像翻转,它不会改变向量的长度。 - **$\Sigma$ (奇异值矩阵):** 这是一个 $m \times n $ 的对角矩阵。 - 除了主对角线上的元素外,其余元素均为 0。对角线上的非负元素 $\sigma_i$ 称为奇异值,并且通常按照从大到小的顺序排列($\sigma_1 \ge \sigma_2 \ge \dots \ge 0$)。 - 在几何上,对角矩阵的作用是在各个坐标轴方向上进行**拉伸或压缩**(缩放)。奇异值的大小代表了在对应维度上拉伸/压缩的力度。 - **$U$ (左奇异矩阵):** 这是一个 $m \times m$ 的正交矩阵。 - 它的列向量被称为左奇异向量。 - 同样,它在几何上代表另一次在目标空间中的旋转或镜像翻转。 可以把矩阵 $A$ 看作是一个线性变换:当你把矩阵 $A$ 乘上一个向量 $\mathbf{x}$ 时(即 $A\mathbf{x}$),你实际上是在对空间中的点 $\mathbf{x}$ 进行移动。SVD 告诉我们,无论这个矩阵 $A$ 的变换看起来有多么复杂(比如把一个高维空间压扁、扭曲成一个低维空间),这个过程都可以被严格拆解为三个连贯的简单动作: 1. **第一步(乘以 $V^T$):旋转。** 先把原始空间(输入空间)旋转一下,让原始的坐标系对准即将被拉伸的方向。 2. **第二步(乘以 $\Sigma$):缩放。** 沿着新的坐标轴方向,有的方向被拉长,有的方向被压扁。如果 $\Sigma$ 中有奇异值为 0,或者矩阵是长方形的,这一步还会发生维度的“坍塌”(降维)。此时,一个完美的圆(或球面)会变成一个椭圆(或椭球面)。 3. **第三步(乘以 $U$):再次旋转。** 把拉伸完的椭圆,再次旋转到目标空间(输出空间)的最终位置。 > 简而言之:任意线性变换 = 旋转 $\to$ 缩放 $\to$ 旋转。 ##### 奇异值分解的意义 SVD 最有用的特性在于它将奇异值**按从大到小排列**。 奇异值 $\sigma_i$ 越大,说明在这个特定方向上的拉伸幅度越大,这个方向上包含的“信息量”或“能量”就越多。很多时候,前 10% 的奇异值之和,就占了所有奇异值总和的 99%。 这意味着,我们可以把那些很小的、接近于 0 的奇异值直接丢弃(当作噪声或冗余细节),只保留最大的前 $k $ 个奇异值及其对应的奇异向量。这样我们就能用一个极小的存储空间(低秩近似)去无限逼近原始的庞大矩阵。这就是图像压缩、降维和提取数据核心特征的数学根基。 ##### 奇异值的求解 1. 构造并求解 $A^T A$ 的特征值和特征向量。首先,计算矩阵乘积 $A^T A$。这会得到一个 $n \times n$ 的对称方阵。接着,求出 $A^T A$ 的所有特征值 $\lambda_i$ 和对应的特征向量 $\mathbf{v}_i$。 - 求解特征方程:$\det(A^T A - \lambda I) = 0$ 得到特征值。 - 代入特征值求解 $(A^T A - \lambda I)\mathbf{v} = 0$ 得到特征向量。 2. 组装右奇异矩阵 $V$。将上一步求得的特征向量 $\mathbf{v}_i$ 进行单位化(化为长度为 1 的向量)。然后,将这些单位特征向量按列拼接起来,就得到了 $n \times n$ 的正交矩阵 $V$。 * 拼接时,必须按照特征值 $\lambda_i$ 从大到小的顺序排列这些特征向量。 3. 组装奇异值矩阵 $\Sigma$:奇异值 $\sigma_i$ 其实就是特征值 $\lambda_i$ 的算术平方根,即 $\sigma_i = \sqrt{\lambda_i}$。将这些奇异值按从大到小的顺序放在对角线上,其余位置补 0,就得到了 $m \times n $ 的对角矩阵 $\Sigma$。 4. 计算左奇异矩阵 $U$:虽然理论上,你可以通过求 $A A^T$ 的特征向量来得到 $U$。但实际上千万不要这么做,因为分别求 $V$ 和 $U$ 会导致符号不匹配(特征向量乘上 -1 依然是特征向量,这会让 $A = U \Sigma V^T$ 的等式不成立)。正确的做法是使用公式直接推导:因为 $A = U \Sigma V^T$,两边同乘 $V$,得到 $AV = U \Sigma$。展开后,对于每一个非零奇异值 $\sigma_i$,都有对应的关系:$$\mathbf{u}_i = \frac{1}{\sigma_i} A \mathbf{v}_i$$ 你可以直接用求好的 $\mathbf{v}_i$ 和 $\sigma_i$ 算出来 $\mathbf{u}_i$。将这些 $\mathbf{u}_i$ 按列排好,就得到了 $m \times m$ 的矩阵 $U$。(如果 $A$ 不是满秩的,导致 $\sigma_i = 0$,则剩余的 $\mathbf{u}_i$ 可以通过施密特正交化来补全,使其构成完整的正交基)。 上面是基于特征值求解的“解析法”,在纯数学上非常完美,但在计算机代码(如 PyTorch、NumPy)中,几乎从来不这么算。原因在于第一步计算 $A^T A$时。如果 $A$ 矩阵中有一个非常小的数(例如 $10^{-8}$),一旦计算 $A^T A$,这个数就会变成 $10^{-16}$。在计算机的浮点数精度限制下,这个极其微小的数值会被直接当作 0 抹除掉,这被称为条件数平方问题,会导致严重的精度丢失。 现代数值线性代数库通常采用迭代法,直接对 $A$ 进行操作,绕过计算 $A^T A$ 的陷阱: 1. **Golub-Kahan 双对角化法:** 先通过一系列正交变换(如 Householder 反射),把 $A$ 变成一个双对角矩阵。然后再用一种改良版的 QR 迭代算法,把对角线外的值渐渐“逼”成 0,最后剩下的对角线就是奇异值。 2. **随机化 SVD(Randomized SVD):** 当面对几千万维度的大数据(比如整个互联网的词频矩阵)时,精确解算要耗费数月。工程师会用一组高斯随机向量去乘矩阵 $A$,捕捉到它“最胖”的那几个维度(即信息量最大的方向),然后在压缩后的极小空间里进行 SVD。这种方法只求前 $k $ 个最大的奇异值,能在几秒钟内完成,牺牲一点点精度换来万倍的速度提升,这是现代 AI 推荐系统和降维算法的基石。 ### 概率论 **随机试验:**一个合格的随机试验必须满足以下三个条件: - **可重复性**:可以在相同的条件下重复进行。 - **结果明确性**:每次试验的所有可能结果都是明确已知的,且不止一个。 - **不可预测性**:在进行试验之前,无法确定具体会发生哪一个结果。 **样本空间 ($\Omega$)**:将试验**所有可能**的结果收集起来构成的集合。 **样本点**:样本空间中最基本、不可再分的结果。 - **离散情形**:如掷六面骰子,$\Omega = \{1, 2, 3, 4, 5, 6\}$。 - **连续情形**:如仪器测量膨胀度(物理极限 0~50),$\Omega = [0, 50] $,样本点有无限多个。 **事件:**在概率论中,事件本质上是样本空间 $\Omega$ 的一个**子集**(包含一个或多个样本点),通常用大写字母 $A, B, C$ 等表示。 - **必然事件**:一定会发生的事件,等于整个样本空间 $\Omega$。 - **不可能事件**:绝对不会发生的事件,用空集 $\emptyset$ 表示。 - **随机事件**:可能发生也可能不发生的事件。 - *例 1(离散)*:掷骰子时“掷出偶数”,事件 $A = \{2, 4, 6\}$。 - *例 2(连续)*:膨胀度“测得数值大于 15”,事件 $B = \{x \mid 15 < x \le 50\}$。 #### 概率公理化定义 只要一个函数 $P$ 满足以下三条绝对不可违反的“铁律”,它就可以被称为概率: - **非负性**:对于任何事件 $A$,概率不小于 0,即 $P(A) \ge 0$。(如同物理学中质量不能为负)。 - **规范性**:必然事件的概率为 1,即 $P(\Omega) = 1$。(确立了概率的上限“百分之百”)。 - **可数可加性**:如果两个事件**绝对不可能同时发生**(即“互斥事件”),那么“这两个事件中任意一个发生”的概率,等于它们各自发生的概率之和。即对于互斥事件 $A$ 和 $B$:$P(A \cup B) = P(A) + P(B)$。 #### 确定概率数值的模型 **古典概型**:适用于所有基本结果**等可能**的情形(如完美硬币、均匀骰子)。*(注:一旦各结果可能性不再相等,此方法即失效)* $$ P(A) = \frac{\text{事件 } A \text{ 包含的样本点数}}{\text{总样本点数}} $$ **几何概形**:古典概型的连续推广。样本空间是一个几何区域,且样本点落在该区域内各处的可能性相等。概率大小由几何测度(长度、面积、体积)决定。解决了“无限个等可能结果”的计算问题,是理解连续型随机变量(如均匀分布)的直观基础。 **频率学派**:认为概率是客观存在的物理常数。单次试验不可预测,但大量重复后,频率会稳定于某一常数。这是传统科学实验与工程统计的基础。 **贝叶斯学派**:认为概率是主观置信度,会随新证据不断被修正(从“先验概率”更新为“后验概率”)。这是现代机器学习与人工智能的理论基石。 #### 条件概率 在已知事件 $A$ 发生的条件下,事件 $B$ 发生的概率,记作 $P(B|A)$。 $$ P(B|A) = \frac{P(A \cap B)}{P(A)}(P(A) > 0) $$ 乘法公式:将条件概率公式变形,即可得到两事件同时发生的概率,等于“第一个先发生”的概率,乘以“在第一个发生的条件下,第二个发生”的概率。 $$ P(A \cap B) = P(A) \cdot P(B|A) $$ 全概率公式:如果把复杂的样本空间 $\Omega$ 像切蛋糕一样切成互不重叠的几块(即完备事件组 $A_1, A_2, \dots, A_n$),那么任何一个事件 $B$ 的总概率,就是它在每一块里发生的概率的加权总和。 $$ P(B) = \sum_{i=1}^{n} P(A_i) \cdot P(B|A_i) $$ #### 贝叶斯定理 用于在观测到新证据后,反向更新我们对原因的认知。 $$ P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)} $$ - **$P(A)$ 先验概率 (Prior)**:在看到任何新证据之前,你对原因 $A$ 发生的初始置信度(源于历史经验或常识)。 - **$P(B|A)$ 似然度 (Likelihood)**:如果原因 $A$ 确实发生了,那么出现证据 $B$ 的概率有多大(衡量假设与证据的契合度)。 - **$P(B)$ 边缘概率 / 证据常数 (Marginal)**:在所有可能的情况下,证据 $B$ 发生的总概率。通常需要用全概率公式展开:$P(B) = P(B|A)P(A) + P(B|A^c)P(A^c)$。 - **$P(A|B)$ 后验概率 (Posterior)**:在观测到确凿证据 $B$ 之后,对原因 $A$ 发生概率的重新评估(计算的最终目标)。 贝叶斯定理应用的实际例子:假设某种罕见病在人群中的发病率为 1%。有一种试纸专门检测这种病: - 如果你有病,试纸有 **99%** 的概率呈阳性(真阳性率)。 - 如果你没病,试纸依然有 **5%** 的概率呈阳性(假阳性率,也就是误诊)。 **问题:** 假设你去查了一下,结果呈阳性!请问你真正得病的概率是多少? 直觉可能会告诉你:“试纸准确率高达 99%,那我肯定完蛋了,得病概率至少有 90% 吧?” **用贝叶斯公式计算:** - **假设 $A$**:你真的得了病。先验概率 $P(A) = 0.01$(因为人群发病率就是 1%)。 - **证据 $B$**:检测呈阳性。 - **似然 $P(B|A)$**:真有病且测出阳性的概率 $= 0.99$。 - **证据概率 $P(B)$**:无论你有病没病,测出阳性的总概率。这里要用**全概率公式**把它拆开: $P(B) =$ (有病且测出阳性) $+$ (没病但测出阳性) $P(B) = P(B|A)P(A) + P(B|\text{没病})P(\text{没病})$ $P(B) = 0.99 \times 0.01 + 0.05 \times 0.99 = 0.0099 + 0.0495 = 0.0594$ 现在,我们把数值代入贝叶斯公式求后验概率 $P(A|B)$:$$P(A|B) = \frac{0.99 \times 0.01}{0.0594} \approx 0.1667$$ 这样得到的结论是:即使试纸呈阳性,你真正得病的概率也只有 16.67%! 你大概率(超过 83%)是个健康人,只是运气不好撞上了那 5% 的假阳性。这是因为在整个人群的基数中,健康人(99%)远多于病人(1%),所以“没病但被误诊”的绝对人数,其实比“真有病且被查出”的人数还要多。 #### 期望 数学期望:(通常记作 $E[X]$)是随机变量取值的**加权平均**。它代表了试验多次后,我们预期得到的“平均水平”。如果把概率分布看作一个具有质量的物体,期望就是这个物体的**物理重心**。它告诉我们随机变量“集中”在哪里。比如,即便某个理财产品有时亏损有时盈利,只要它的期望收益是正的,长期来看它就是盈利的。 根据随机变量类型的不同,期望的计算方式也有所不同: - **离散型随机变量(例如掷骰子):**将每一个可能出现的结果与其发生的概率相乘,然后把所有的乘积加起来 $$ E(X)=\sum_{i}x_i p_i $$ > 掷一个公平的六面骰子,点数的期望为:$1\times\frac{1}{6}+2\times\frac{1}{6}+3\times\frac{1}{6}+4\times\frac{1}{6}+5\times\frac{1}{6}+6\times\frac{1}{6}=3.5$。 > > 请注意,期望值不一定是你每次实际能掷出的那个具体数值(骰子上没有3.5点),它是大量结果的平均。 - **连续型随机变量(例如人的身高、气温):**使用积分来代替求和,将变量取值与其概率密度函数相乘后求积分。 $$ E(X)=\int_{-\infty}^{\infty}x f(x)dx $$ 期望的性质:常数的期望就是常数本身,且期望具有可加性。 $$ E(aX+b)=aE(X)+b \\ E(X+Y)=E(X)+E(Y) $$ #### 方差 如果仅仅知道期望,我们往往无法全面了解数据分布情况。例如,两组数据 $A=[5,5,5]$ 和 $B=[0,5,10]$ 的期望都是5,但显然B的波动要大得多。方差就是用来衡量这种波动大小的指标。 方差是**每个数据点与期望值之差的平方的期望**。换句话说,它衡量的是数据偏离中心的平均距离的平方。 $$ Var(X)=E[(X-E(X))^2] $$ 在实际计算中,我们经常使用它的一个推导公式,计算起来更简便: $$ Var(X)=E(X^2)-[E(X)]^2 $$ 标准差:因为方差对偏差进行了平方操作,导致它的量纲(单位)也变成了原来的平方(比如原来是“米”,方差就是“平方米”)。为了让波动指标的单位和原数据保持一致,我们对期望开平方,这就是标准差 $$ \sigma=\sqrt{Var(X)} $$ 方差的性质: * **非负性:** 方差永远大于或等于0。如果方差为0,说明随机变量是一个恒定的常数。 * **平移与缩放:** 加上一个常数不会改变数据的波动范围,但乘以一个常数会将方差放大该常数的平方倍。 $$ Var(aX+b)=a^2Var(X) $$ ## 机器学习 ### 线性回归 #### 梯度下降 #### 归一化 #### 正则化 #### lasso回归 ### 线性分类 ### 无监督学习
💾 保存修改
取消返回
准备离开了吗?
确定要退出管理员账号并返回访客模式吗?
取消
确定退出